
The software applications we utilize are absolutely productive and wonderful tools to have, but they’re also used as attack vectors to gain a leverage inside the organization that use these applications. That’s why it’s important that we secure the development of software from start to finish.
Historically, the software development team and the quality assurance team worked together to create software, leaving the IT operations team to examine the finished product for any security defects that might leave their network and systems vulnerable to certain software exploits. This led to a frustrating conflict between the software developers and the IT operations team because when the IT operations team discovered a vulnerability in the software, they would send it back to the development and quality assurance teams. The the biggest underlying problem was that the software development and quality assurance team were mostly likely working on another software project, in which case they felt the IT operations team was a thorn in their side.
Fixing this required a collaborative effort in which the software development, quality assurance, and IT operations team worked together throughout the Software Development Life Cycle (SDLC). This multi-functional undertaking of the software development team and the IT operations team was given the name “DevOps.” However, more and more organizations are adding in a cybersecurity team into this collective effort, which has led to the development of the “DevSecOps,” accordingly.
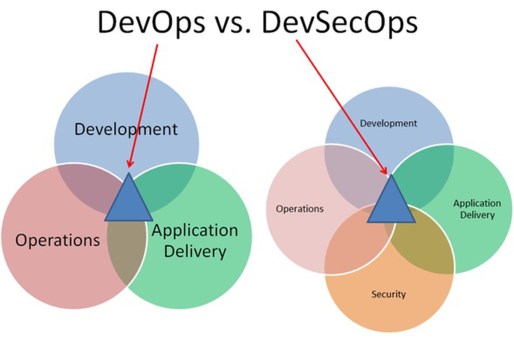
How can we secure our software and make it harder to exploit for the bad guys? Fortunately, there are a lot of ways to accomplish this, but many software developers like to put function and user acceptance before security. Here are some of the ways in which we can practice secure coding.
Input Validation
This is perhaps the single-most important things software developers should do. Input validation allows us to check the validity of user input before submission. This means that the application checks to ensure that what the user is attempting to submit to the application is what it’s supposed to be and not some type of malicious code or query. A good example of this is a patient portal login field for a health care application. This application is used by patients, doctors, and hospital staff as a database to store information. The application itself follows important access control principles and restricts users access to only the information they are allowed to see. The proper input of the application’s login field would be a username or password, but without input validation, users can submit whatever they wish to the application. They can submit bogus SQL queries for SQL injections to retrieve sensitive information, write data to a buffer to unleash a buffer overflow attack and trick the system into executing the attacker’s code, or submit malicious code for Cross-Site Scripting (XSS) attacks. These are all attacks that exploit software, but can be prevented if we sanitize user input.
Input validation can be performed by verifying proper characters. For example, you would expect a valid name in a “Name” field to contain only letters. Likewise, the Social Security Number (SSN) field would contain only numbers following an identical format to XXX-XX-XXXX. Anything else would either be removed or rejected by the application. We can also implement bounds checking, which ensures a variable fits into a specific boundary or range. For example, if the max number of items you can purchase is 10 items, there would be a mechanism to ensure that the quantity is 10 items or less.
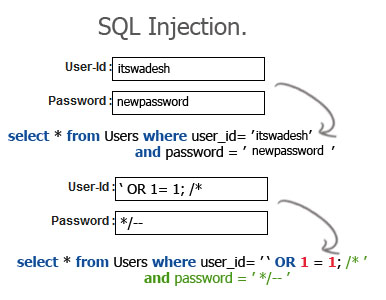
- SQL injection attack against the login field. Reprinted from “SQL Injection,” by Swadesh Programming Blog, 2011.
Many SQL injection attackers use specific characters in their queries, such as the dash (-), apostrophe (‘), and equal sign (=). These aren’t normally things a user submits to an application; henceforth, it makes sense to restrict this type of input.
Error- and Exception-Handling
One often overlooked aspect of input validation is how the system responds to the user when they submit malicious input. Sometimes, a system responds with an error that reveals useful information to an attacker. For instance, some servers unneededly respond to user input with too much information. The image below shows a server responding to an error. We can see that the server’s IP address, host name, login user table name, and the page storing the location to the Web server are leaked.

Server error reveals too much information to the user. Reprinted from “Exploiting by Information Disclosure, Part 1,” by Yadav, A., 2014.
Incidents such as these can be fixed during software development, a process called “error- and exception-handling.” It’s better for the application to respond with a customized error page rather than the real one. This prevents attackers from getting too much valuable information.
Parameter Validation
A “parameter” is a type of variable in programming language used to pass information between functions or procedures. The information being passed is called an “argument,” hence the reason why a parameter is sometimes called a “formal argument.” As a common scenario of improper parameter validation, many web applications are using “cookies” to too keep track of thousands of web site visitors. Cookies are just strings of characters that uniquely identify a visitor’s session. The cookie is stored on the visitor’s system and whenever the visitor re-visits the web site again, the web browser presents the cookie to the web server for identification. In this way, software developers eliminate the need for their users re-login. For example, you can login to your G-Mail account and then close your Web browser. When you re-open your Web browser and navigate back to G-Mail, you won’t have to log back in. Only until you log off or delete your cookie information will you have to log back in.
However, in session hijacking attacks, cookies are stolen through MitM or XSS attacks. Accessing or modifying cookies isn’t something most users do and it’s therefore something web developers don’t keep in mind when they design their software. Parameter validation allows the application to distinguish between user input data and code, regardless of what the user submits. Prepared statements and stored procedures can validate a parameter to prevent these types of attacks.
HTML code
Right-click to bring up the drop-down menu and then click “Inspect.” Developers sometimes leave a lot of metadata and unnecessary information into their HTML source code. This could reveal the structure of the directory or internal network information. I’ve even noticed passwords lying in the HTML source code. Attackers will inspect the HTML source code for any relevant information that gives them useful details during their active reconnaissance.
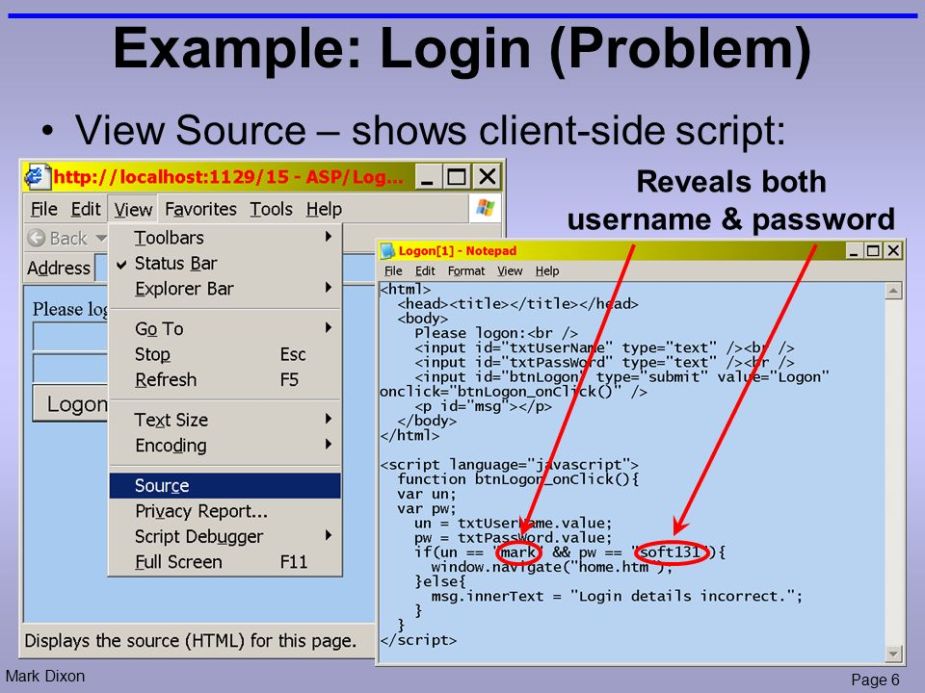
HTML code reveals username and password.
This inherent threat is often considered unimportant or forgotten by developers.
Static Code Analysis
Static code analysis means exactly what it says: we are analyzing the source code without executing the program. This is usually performed automatically by another tool, such as OWASP’s Lapse+ for Java EE applications. The image below shows Lapse+ discovering an SQL injection vulnerability by analyzing the source code.
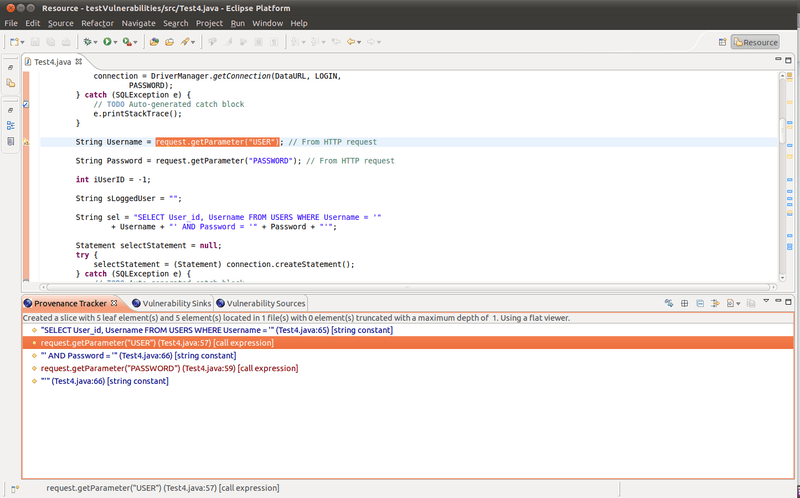
Lapse+ in action. Reprinted from “OWASP LAPSE Project,” by OWASP, 2017.
Obviously, by performing static code analysis, you wont find any vulnerabilities evident during run time. For that, the software would require additional testing.
Code Reviews
Code reviews are similar to static code analysis, except we are recruiting someone other than the author (e.g., an internal team or a third-party developer) to systematically review or examine the instructions that comprise a piece of software. It’s identical to having someone proofread your work.
Code reviews might reveal sloppy or hard-to-find defects in the code that the original software developer might have missed.
Regression Testing
Secure coding is a trial-and-error process because developers frequently find themselves going back to make adjustment after adjustment. It’s a cat-and-mouse game; we find vulnerabilities and we patch them again-and-again. No software is ever written securely on the first attempt. All the changes and modifications made to the software can sometimes inadvertently break a feature, function, or security characteristic that the software is supposed to perform.
To prevent this, we use “regression testing.” This is a process that verifies whether or not the changes made to the source code have compromised any features or security characteristics to the software.
Canaries
“Canaries,” or “canary words,” are meant to prevent buffer overflow attacks. They are known values that are placed between a buffer and control data on the stack to monitor buffer overflows. When the buffer overflows from a buffer overflow attack, the first data to be corrupted will be the canary and not the memory where malicious code can be injected and executed.
Web Application Vulnerability Scanning
Web application vulnerability scanners, such as CIRT.net’s “Nikto,” can assess web server software vulnerabilities via a command-line interface. Web application vulnerability scanners attempt to identify common web application vulnerabilities, such as misconfigurations, authentication vulnerabilities, information leaks, improper HTTPS use, and so on.
Interception Proxies
Burp Suite, ZAP, and Vega are all interception proxies you can use to test the security of your web applications. Proxy servers sit between users and a web server. They act as an intermediary device that forwards and accepts information on behalf of the user. For example, if a proxy server is sitting between an employee and a Web server out on the Internet, the employee’s request for the Web site will have to go through the proxy. The proxy then makes the connection to the Web server on the employee’s behalf. Accordingly, all information sent from the Web server is relayed back through the proxy and to the employee. 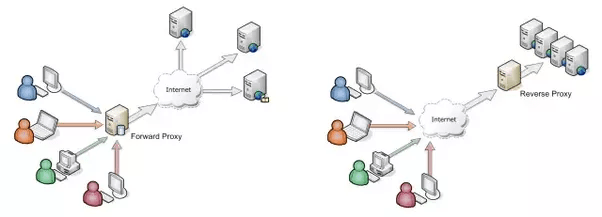
Proxies are usually installed to incorporate access control, caching for quicker referencing, NAT, content filtering, and security, but they can also be used for testing web applications. Using an interception proxy, we can see all information being passed between the client and the server, allowing us to detect any vulnerabilities or leaked information.
Fuzz and Stress Testing
“Fuzzing” is the process of sending specific, random, or unexpected data to a program for the purposes of discovering some unintended vulnerabilities, such as an unnecessary error pages, crashes, buffer overflows, or validation flaws. If a vulnerability is discovered, it can be fixed. Some popular fuzzing tools are PortSwigger’s “Untidy,” OWASP’s “Peach Fuzzer” suite, and Microsoft’s “SDL Fuzzer.”
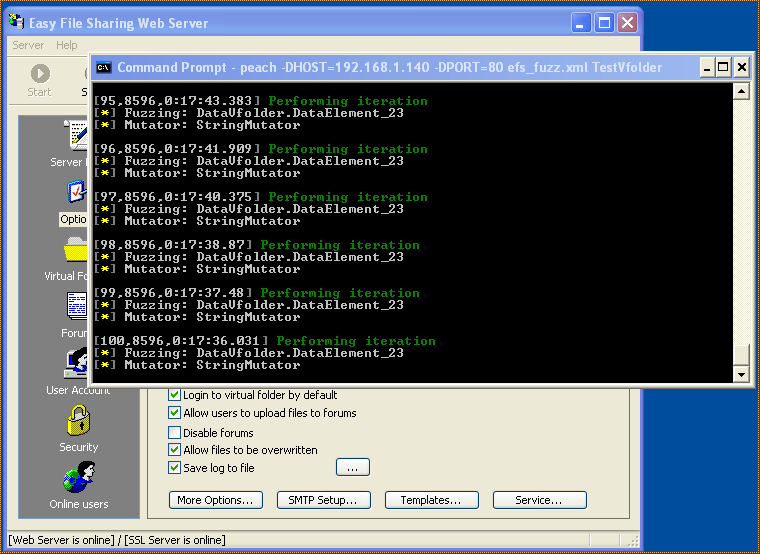
Fuzz testing a server. Reprinted from “From fuzzing to 0-day,” by Techorganic, 2014.
Similar to fuzz testing is “stress testing,” except in this case, testers place extreme demands on the software. With stress testing, we are either giving “too much” of something or “too little” of something and observing how the software responds to these conditions. When testing for too much of something, we’re usually initiating thousands of simultaneous connections to see how much it takes to overwhelm the software. On the other hand, testing too little of something involves some aspect of “resource starvation” in which we are taking away substantial amounts of network bandwidth, CPU, or memory. Any good software wouldn’t fail under these circumstances, but rather gracefully degrade.
Conclusion
If you’re interested in additional secure coding concepts, you can look into SEI at Carnegie-Mellon university. These guys have an overall focus in secure software engineering practices, some of which were already mentioned here.
References
Maymi, F. J., Chapman, B. (2018). All-in-One CompTIA CSyA+ Cybersecurity Analyst Certification Exam Guide CS0-001. McGraw-Hill Education: New York, NY.
Swadesh Programming Blog. (2011). SQL Injection. Retrieved from https://itswadesh.wordpress.com/tag/sql-injection/
Yadav, A. (2014). Exploiting by Information Disclosure, Part 1. InfoSEC Institute. Retrieved from http://resources.infosecinstitute.com/exploiting-information-disclosure-part-1/#gref

[…] via Secure Software Development Practices — The Cybersecurity Man […]
LikeLiked by 1 person